대회 기간이 2024년 7월 9일부터 22일까지지만, 수업 없이 온전히 대회에 시간을 쓸 수 있는 시간은 4일뿐, 시간이 부족하여 시도해보지 못한것들이 많아 아쉽다.
대회 개요
2007.01.01 ~ 2023.06.30 시점의 데이터를 이용하여 이후 3개월(2023.07.01 ~ 2023.09.26)의 아파트 실거래가를 예측하는 대회이다.
Feature 수는 target 포함해서 52개이고, 학습 데이터는 2007.01.01 ~ 2023.06.30 기간동안 1,118,822개이다. 목표는 2023.07 ~ 2023.09 기간동안 아파트 실거래가 9272개를 예측해야 한다.
- 팀 구성 및 컴퓨팅 환경 : 5인 1팀. 인당 RTX3090 서버를 VSCode 와 SSH 로 연결하여 사용
- 협업 환경 : Notion, GitHub
- 의사 소통 : Slack, Zoom
대회 결과
우리 팀은 12팀중에서 최종 4등을 하였다. (Public 7등, Private 4등)

EDA

제공되는 데이터에는 결측치가 상당히 많다. 보다 자세한 EDA 는 나보다 뛰어난 팀원분께서 해주셔서 나는 자세히 진행하지 않았다. 저 많은 결측치를 제대로 채워 넣을 시간과 방법이 부족하니, 일단 나는 최대한 간단한 데이터에서부터 시작하기로하고 결측치가 많은 피처들은 모두 삭제했다.
단, 좌표X, Y 는 결측치를 채우면 이걸 기반으로 다양한 피처를 추가할 수 있어 채우기로 했다.
좌표X, Y 결측치 채우기
다행히 지번주소는 결측치가 거의 없어서 이것을 기반으로 좌표X, Y 를 구하기로 했다. 좌표 X, Y 는 각각 경도, 위도에 해당한다. 팀원분께서 방법을 찾아주셨다.
첫번째 방법은 geopy.geocoders 패키지를 사용하는 방법인데, 결측치가 많아서 쓸 수가 없었다.
https://parkgihyeon.github.io/project/geocoding-api/
[지오코딩 API: 파이썬] 주소로 위도 경도 찾기, 좌표로 주소 얻기
🔔 지오코딩과 역지오코딩을 간단하게 알아보겠습니다.
parkgihyeon.github.io
두번째 방법은 카카오 API 를 사용하는 방법인데, 이것 또한 결측치가 많아서 사용하기 곤란했다.
세번째 방법은 네이버 Maps API 를 사용하는 방법인데, 요건 훨씬 결측치가 적었다.
# https://api.ncloud-docs.com/docs/ai-naver-mapsgeocoding-geocode
import requests, json
def getAddrElement(addrDict, addrType):
for elemDict in addrDict['addressElements']:
if elemDict['types'][0] != addrType: continue
return elemDict['longName']
return ""
def getJibunAddr(addrDict):
ret = getAddrElement(addrDict, "SIDO")
ret += " "
ret += getAddrElement(addrDict, "SIGUGUN")
ret += " "
ret += getAddrElement(addrDict, "DONGMYUN")
ret += " "
ret += getAddrElement(addrDict, "LAND_NUMBER")
return ret
def getRoadAddr(addrDict):
ret = getAddrElement(addrDict, "SIDO")
ret += " "
ret += getAddrElement(addrDict, "SIGUGUN")
ret += " "
ret += getAddrElement(addrDict, "ROAD_NAME")
ret += " "
ret += getAddrElement(addrDict, "BUILDING_NUMBER")
return ret
def get_location(address, addrType):
url = 'https://naveropenapi.apigw.ntruss.com/map-geocode/v2/geocode?query=' + address
headers = {"X-NCP-APIGW-API-KEY-ID": "~~your-key-id~~", "X-NCP-APIGW-API-KEY": "~~your-api-key~~"}
api_json = json.loads(str(requests.get(url,headers=headers).text))
print(f"api_json = {api_json}")
if api_json['status'] == 'OK' and len(api_json['addresses']) > 0:
# 2개 이상인 경우도 있을지 확인하기위해..
is_multi_addr = len(api_json['addresses']) > 1
x = "0"
y = "0"
road_address = ""
for addrDict in api_json['addresses']:
if addrType == 'land':
if getJibunAddr(addrDict) != address: continue
else:
if getRoadAddr(addrDict) != address: continue
x = addrDict['x']
y = addrDict['y']
road_address = getRoadAddr(addrDict)
break
if x != "0":
return { "X": x, "Y": y, 'road_address': road_address, 'is_multi_addr': is_multi_addr }
return {"Y": "0", "X": "0"}
# crd = get_location("서울특별시 강남구 개포동 12")
# print(crd)
지번주소로 검색 안되는 것은 도로명주소로 검색해서 채워 넣었고, 이 둘로도 검색이 안되는 주소는 구글링해서 가장 가까운 지번주소의 위도, 경도 값으로 채워 넣었다.
이렇게 결측치가 채워진 좌표 X, Y 를 팀원분들에게 공유 드렸다. 다들 뛰어나신 분들이라서 나도 뭔가 팀에 기여를 하고 싶었는데, 다행히 팀원분들이 유용하게 사용하신 것 같다. 이것을 기반으로 가까운 지하철, 버스, 초등학교 등등의 피처를 만드셨다.
사용한 외부 데이터
이전 EDA 프로젝트에서 아파트 실거례가는 KB부동산 매수우위지수, 기준금리, 기대인플레이션율과 관련이 많았어서 이들 피처를 추가했다. 또한 초품아라는 말이 있을 정도로 아파트에서 초등학교가 가까운걸 선호하기 때문에 최단거리 초등학교 피처도 추가했다. 당연히 대중교통 또한 중요하니 지하철 피처를 추가했다.
최단거리 초등학교 피처 만들기
좌표X, Y 는 이제 결측치가 없다. 팀원분께서 서울시 초등학교 목록 정보를 구해주셔서, 각 아파트에서 가장 가까운 초등학교 및 거리를 피처로 만들면 괜찮겠다는 생각이 들었다.
지구는 둥글기 때문에 단순히 유클리드 거리로 계산하면 안되고, 하버사인 공식(Haversine Formula) 을 사용해야 한다. 다행히 파이썬 패키지가 있다.
내가 처음 개발 했을때는 무식하게 모든 초등학교 좌표와 거리를 구하고 그중에서 가장 작은 값을 취하도록 했는데, 이렇게 했더니 모든 데이터에 대해 완료 하려면 대략 8시간 정도 걸릴 것 같았다. 이 얘기를 팀원께 얘기했더니 좋은 솔루션을 알려주셨다! 감사합니다!
import numpy as np
from sklearn.neighbors import BallTree
from haversine import haversine, Unit
apartment_coords = dt[['좌표Y_2', '좌표X_2']].values
elemSchool_coords = dt_elemSchool[['위도', '경도']].values
tree = BallTree(elemSchool_coords, metric='haversine')
_, indices = tree.query(apartment_coords, k=1) # distances 는 값이 이상하여 따로 계산하자.
distances = np.array([haversine((ac[0], ac[1]), (elemSchool_coords[i, 0], elemSchool_coords[i, 1]), unit=Unit.KILOMETERS)
for ac, i in zip(apartment_coords, indices)])
dt['최단거리초등학교명'] = dt_elemSchool.loc[indices.flatten(), '학교명'].values
dt['최단거리초등학교Km'] = distances
BallTree 라는 클래스를 사용하면 내가 지정한 좌표와 가장 가까운 좌표 k 개를 순식간에 뽑아준다. 참고로 BallTree 말고도 비슷한 기능을 하는 다른 클래스가 있다.
모델 선정
팀원분께서 앙상블을 하면 결과가 좋아지더라는 말을 해주셔서 Random Forest, LightGBM, XGBoost, 이렇게 3개를 사용하기로 했다. GradientBoosting, LinearRegression 또한 사용 했었는데, 제외했다. 선정 이유는 다음과 같다.
| Model | 장단점 |
| Random Forest | 훌륭한 성능, 빠른 학습 속도 |
| LightGBM | 훌륭한 성능, 빠른 학습 속도 |
| XGBoost | 훌륭한 성능, 빠른 학습 속도 |
| Linear Regression | 낮은 성능 |
| Gradient Boosting | 느린 학습 속도(제일 느림) |
초반에는 시간을 절약하기위해 Random Forest 만으로 학습을 했다.
평가 결과
| 피처 | 모델 | RMSE | R-squared | MAE | Submission |
| (Train / Valid) | (Train / Valid) | (Train / Valid) | (public/private) | ||
| 기본 (구, 동, 번지, 전용면적, 계약년, 계약월, 계약일, 건축년도, 좌표X_2, 좌표Y_2) | Random Forest | 2627.0079 / 6896.9111 | 0.9968 / 0.9781 | 1213.3631 / 3149.4610 | |
| (n_estimators = 100) | |||||
| + 최단거리 초등학교 | Random Forest | 2613.8844(-13.1235) / 6839.7912(-57.1199) | 0.9968 / 0.9785(+0.0004) | 1205.9546(-7.4085) / 3129.0467(-20.4143) | |
| (n_estimators = 100) | |||||
| + 지하철 | Random Forest | 2604.5450(-9.3394) / 6812.7848(-27.0064) | 0.9968(0) / 0.9787(+0.0002) | 1204.0203(-1.9343) / 3120.9234(-8.1233) | |
| (n_estimators = 100) | |||||
| + KB 매수우위지수 | Random Forest | 2598.4469(-6.0981) / 6789.7600(-23.0248) | 0.9969(+0.0001) / 0.9788(+0.0001) | 1196.4952(-7.5251) / 3096.3142(-24.6092) | |
| (n_estimators = 100) | |||||
| + 기준금리 | Random Forest | 2594.1784(-4.2685) / 6777.5173(-12.2427) | 0.9969(0) / 0.9789(+0.0001) | 1193.6840(-2.8112) / 3087.8560(-8.4582) | |
| (n_estimators = 100) | |||||
| + 기대인플레이션율 | Random Forest | 2589.5867(-4.5917) / 6790.7117(+13.1944) | 0.9969(0) / 0.9788(-0.0001) | 1190.8269(-2.8571) / 3082.1282(-5.7278) | 17778.0489 / 14772.0250 |
| (n_estimators = 100) |
| 피처 | 모델 | RMSE | R-squared | MAE | Submission |
| (Train / Valid) | (Train / Valid) | (Train / Valid) | (public / private) | ||
| 변동 없음 | Random Forest | 2589.5867 / 6790.7117 | 0.9969 / 0.9788 | 1190.8269 / 3082.1282 | 17778.0489 / 14772.0250 |
| (n_estimators = 100) | |||||
| LightGBM | 12032.4852 / 12224.9358 | 0.9327 / 0.9313 | 7361.7819 / 7367.3108 | ||
| (n_estimators = 100) | |||||
| XGBoost | 9656.7461 / 10096.6722 | 0.9566 / 0.9532 | 5733.0738 / 5801.5778 | ||
| (n_estimators = 100) | |||||
| Ensemble | 7310.3366(+4720.7499) / 8562.5464(+1771.8347) | 0.9751(-0.0218) / 0.9663(-0.0125) | 4264.3118(+3073.4849) / 4699.6542(+1617.526) | ||
| (n_estimators = 100) | |||||
| 변동 없음 | Random Forest | 2536.4700(-53.1167) / 6757.5607(-33.151) | 0.9970(+0.0001) / 0.9790(+0.0002) | 1174.9233(-15.9036) / 3067.1282(-15) | |
| (n_estimators = 300) | |||||
| LightGBM | 3385.7394(-8646.7458) / 6190.5937(-6034.3421) | 0.9947(+0.062) / 0.9824(+0.0511) | 2083.7721(-5278.0098) / 2865.6689(-4501.6419) | ||
| (n_estimators = 15000) | |||||
| XGBoost | 3991.3679(-5665.3782) / 6686.6565(-3410.0157) | 0.9926(+0.036) / 0.9795(+0.0263) | 2410.3231(-3322.7507) / 3133.3846(-2668.1932) | ||
| (n_estimators = 3000) | |||||
| Ensemble | 2978.0940(+388.5073) / 6014.6606(-776.0511) | 0.9959(-0.001) / 0.9834(+0.0046) | 1751.4562(+560.6293) / 2776.2914(-305.8368) | 16985.3668(-792.6821) / 12281.7758(-2490.2492) |
보기 어려우니 그래프로 보면 다음과 같다.



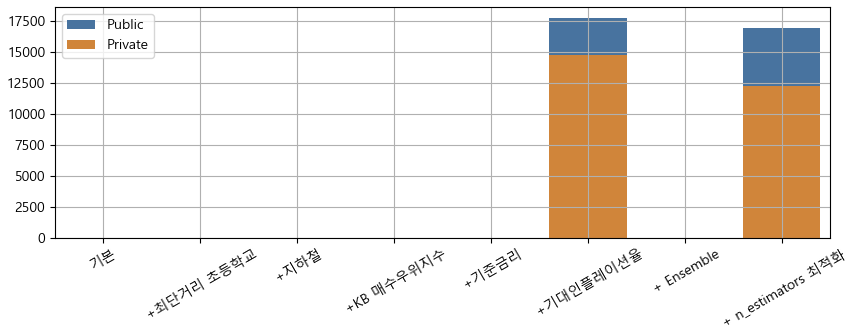
피처를 추가할 때마다 점수가 미세하게 좋아졌다. 단, 기대인플레이션율은 오히려 점수가 안좋아졌는데, 실수로 빼지 못했다.
n_estimators 최적화 없이 앙상블만 하면 오히려 점수가 안좋아졌다. 그러나 n_estimators 를 최적화 한 후 앙상블을 하면, 개별 모델별 최고 점수보다 더 좋은 점수를 보여준다.
이렇게 그래프를 그려놓고 생각해보니, 피처를 추가하지 않고, 앙상블과 n_estimators 최적화만 적용해도 최종 점수와 비슷하겠는데?? 라는 생각이 번쩍 들었다.



그렇다! 추가한 피처는 성능에 큰 영향을 주지 못했다! (물론 성능이 좋아지긴 했다.)
기본으로 제공되는 피처를 너무 우습게 생각했던것 같다.
자체 평가 의견
잘했던 점
- 기본으로 제공되는 피처 중에서 가장 적은 갯수만 선택해서 모델링을 시작한 것.
- 좌표X, Y 의 결측치를 채워서 팀원들에게 공유한 것.
- n_estimators 의 최적의 값을 찾았던 것.
시도 했으나 잘 되지 않았던 것들
- GridSearchCV 로 하이퍼파라미터 튜닝을 시도했는데, 계속 죽어서 시도 못해봤음.
아쉬웠던 점들
- 실험할때 한가지씩만 변경해가며 해야하는데 여러개를 변경해가며 하다보니 정확히 어떤 것 때문에 좋아지고 나빠진것인지 알 수가 없는 경우가 많았음.
- 팀원분들이 많은 피처를 구하고 만드셨는데, 많이 활용해보지 못함.
- 수업 내용중 적용하면 좋을 것들이 많았는데 적용해보지 못함.
- Baseline 코드에서 RandomForestRegressor 객체 생성시 n_jobs = -1 옵션이 있었는데, 내가 이것을 지워서 학습 시간이 너무 오래 걸렸음.
- GPU 사용하는 cuML 을 사용하지 않음.
- 앙상블시 모델별 가중치를 변경해가면서 테스트를 못해봄.
- GridSearchCV 가 실패했으니 Optuna 로 하이퍼파라미터 튜닝을 했었더라면 좋았을 것.
인사이트
- 기본 제공 데이터를 황금같이 여기자.
- RMSE, R^2 가 좋아졌더라도 MAE 가 안좋아지면 Submission 점수가 안좋아 질 수 있다.
- 병목 부분을 빠르게 개선하여 확보한 시간만큼 최대한 실험을 많이 해보자.
소감
이번 팀은 팀원분들이 다들 너무 친절하시고 실력도 좋으셨다. 앞으로의 대회도 이분들과 계속 함께 하고 싶은데 어떻게 될 지 모르겠다.
대회 결과는 12팀중에 4등을 했다. 다른 팀원분들이 했던 내용과 비교하면 내가 한 것은 너무 간소해서 좀 민망하긴했다. 그런데 내가 한 점수가 우리 팀에서 제일 높다니, 어안이 벙벙하다. 온전히 나 혼자서 이런 결과를 만들었다고 결코 생각하지 않는다. 대회 진행하면서 여러모로 팀원분들의 도움을 많이 받았다. 4등이라는 결과는 우리 팀원들이 함께 만든 결과이다.
이번 대회로 배우고 느낀게 많고, 좋은 팀원들과 함께해서 즐거웠다. 다음 대회에서 좀더 좋은 결과를 내고 싶은 욕심이 든다.
'Upstage AI Lab 3기' 카테고리의 다른 글
| Computer Vision Basic (0) | 2024.08.20 |
|---|---|
| [2024-07-30~2024-08-12] Image Classification 대회 (0) | 2024.08.12 |
| 중간 회고 (5) | 2024.07.14 |
| [2024-06-25~07-01] PyTorch (0) | 2024.07.02 |
| [2024-06-18~24] Deep Learning (0) | 2024.07.02 |


