이번 대회 기간은 약 2주지만, 이중 1주는 수업이 있다보니, 최대한 프로젝트 기간을 확보하기 위해 강의를 꼼꼼하게 보진 못했다. 빨리 강의를 봐버리고, 프로젝트를 진행하면서 필요한 내용이 있다면 다시 그 부분을 보기로 했다.
이 글의 내용은 내가 시도 했던 것들만 작성했기 때문에, 우리 팀의 최종 결과와는 차이가 있다.
대회 개요

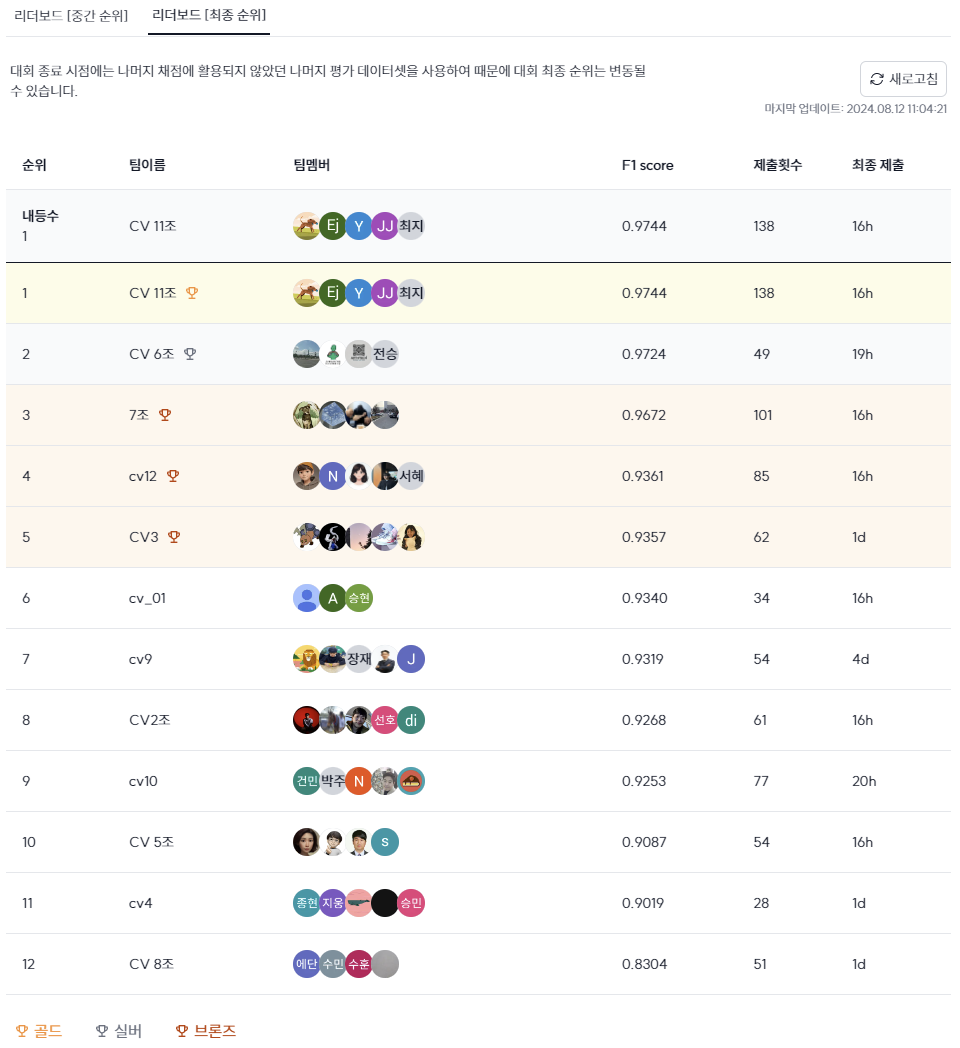
대회 결과
우리 팀은 12팀 중에서 최종 1등을 하였다. (Public 1등, Private 1등) 나의 최고 점수는 팀원이 추천해준 모델( tiny_vit_21m_512.dist_in22k_ft_in1k)로 학습시 서브미션 점수 기준으로 Public 0.9458, Private 0.9386 을 기록했다. 이 점수를 리더보드에 적용해면 4등에 해당하는 점수다.
EDA

클래스별 데이터 갯수를 확인해보면, 위 그림과 같이 데이터의 갯수가 상대적으로 적은 것들이 있다. 그래서 훈련 데이터를 훈련 데이터와 검증 데이터로 분할 시, stratify 매개변수를 사용해서 클래스의 갯수를 고려해서 분할을 하기로 했다.
X_train, X_valid, y_train, y_valid = train_test_split(
train_df,
train_df_target,
train_size=train_size,
stratify=train_df_target,
random_state=random_state
)

위 그림은 7:3 으로 분할된 것을 시각화한 것이다.
Stratified K-Fold Cross Validation 적용
학습 데이터를 7:3 으로 분할해서 학습하다보니, 검증 데이터를 학습에 사용하지 못하여 아까웠다. 그렇다고 학습 데이터를 통째로 학습 시키기엔 검증 데이터가 없다보니 어느 시점에 학습을 멈춰야 할지 알 수 없었다. 멘토님께 여쭤보니 K-Fold Cross Validation 을 사용해보라고 하셨다. 역시 이 방법 밖에 없구나하는 살짝 아쉬운 마음이 들었다. K-Fold Cross validation 을 적용하면 학습에 시간이 너무 오래 걸리기 때문에 나는 이보다 좀더 괜찮은 방법이 있을까 싶었었다.
그래서 나는 5개의 폴드를 사용하기보다는 학습 시간을 줄이기 위해 2개의 폴드를 사용하기로 했다. 또한 데이터의 분포를 고려하기 위해 Stratified K-Fold Cross Validation 을 사용하기로 했다.
from sklearn.model_selection import StratifiedKFold
def get_fold_train_valid_csv_filenames(seed, fold, folds):
fold_train_filename = f'fold_train_SEED_{seed}_{fold}_{folds}.csv'
fold_valid_filename = f'fold_valid_SEED_{seed}_{fold}_{folds}.csv'
return fold_train_filename, fold_valid_filename
def generate_fold_train_valid_csv_files(seed, folds):
df_train = pd.read_csv("datasets_fin/train.csv")
skf = StratifiedKFold(n_splits=folds, shuffle=True, random_state=seed)
for fold, (train_indices, valid_indices) in enumerate(skf.split(df_train, df_train['target'])):
fold += 1
print(f"Fold {fold}/{folds}, train_idx: {type(train_indices)} {len(train_indices)}, {type(valid_indices)} {len(valid_indices)}")
fold_train_filename, fold_valid_filename = get_fold_train_valid_csv_filenames(seed, fold, folds)
# 각 데이터프레임을 임시 CSV 파일로 저장
df_train.iloc[train_indices].to_csv(fold_train_filename, index=False)
df_train.iloc[valid_indices].to_csv(fold_valid_filename, index=False)
StratifiedKFold 클래스가 하는 역할은 각각의 폴드별로 학습 데이터를 학습 데이터와 검증 데이터로 분할해주는게 전부 인것 같다. 그래서 나는 미리 위 코드와 같이 폴드별로 학습 데이터와 검증 데이터를 분할 후 csv 파일로 저장해서, 나중에 폴드별로 이어서 학습을 할 때 사용할 수 있도록 했다.
학습 된 폴더들은 Soft Voting 으로 최종 예측을 했다.
이렇게 Stratified K-Fold Cross Validation 을 사용하여 모든 학습 데이터를 사용하여 학습 한 결과는, 서브미션 점수를 기준으로 0.9407 이 나왔고, 8:2 로 학습한 모델에서는 0.9134 가 나왔었으니, 0.0273 점이 상승했다.
Augmentation 적용
팀원분 중에서 albumentations 로 augmentation 을 적용한 분이 계셔서 나도 그분의 코드를 참고해서 적용했다. 적용 전의 서브미션 점수가 0.2978 였는데, 20배 적용 후 0.4576 으로 대폭 점수가 상승했다. 팀원분께서 작성한 코드라서 첨부하지 못했다.
Hard Voting, Soft Voting 적용
이전 머신러닝 프로젝트에서 앙상블의 위력을 느꼈던지라, 이번에도 앙상블을 하기로 했다. 처음에는 Hard Voting 을 사용해서 각각의 모델들이 예측한 클래스들을 다수결로 최종 예측을 했으나, 모델별로 예측한 결과에 대한 확률을 활용하는 것이 보다 더 정확한 결과를 예측할 것으로 생각되어 Soft Voting 을 최종적으로 사용했다.
def get_preds_list_by_tst_loader(model, tst_loader, device, is_soft_voting=False):
preds_list = []
model.eval()
for image, _ in tqdm(tst_loader):
image = image.to(device)
with torch.no_grad():
preds = model(image)
if is_soft_voting:
soft_preds = F.softmax(preds, dim=1)
preds_list.extend(soft_preds.detach().cpu().numpy())
else:
preds_list.extend(preds.argmax(dim=1).detach().cpu().numpy())
return preds_list
def hard_voting(predictions):
predictions = np.asarray(predictions)
return np.apply_along_axis(lambda x: np.bincount(x).argmax(), axis=0, arr=predictions)
def soft_voting(predictions):
predictions = np.asarray(predictions)
mean_axis0 = np.mean(predictions, axis=0)
# 증강된 데이터에 대한 예측값도 고려하기.
all_targets_count = 모든 클래스 갯수
aug_size = len(mean_axis0) / all_targets_count
assert len(mean_axis0) % all_targets_count == 0
aug_size = int(aug_size)
if aug_size > 1:
bulk_list = []
step = 0
for i in range(0, aug_size):
bulk_list.append(mean_axis0[step:step + all_targets_count])
step += all_targets_count
bulk_list = np.asarray(bulk_list)
mean_axis0 = np.mean(bulk_list, axis=0)
return mean_axis0.argmax(axis=1)
preds_list = []
for model, tst_loader in zip(model_list, tst_loader_list):
preds = get_preds_list_by_tst_loader(model, tst_loader, device, is_soft_voting)
preds_list.append(preds)
# 최종 예측
if is_soft_voting:
final_pred = soft_voting(preds_list)
else:
final_pred = hard_voting(preds_list)TTA (Test-Time Augmentation) 적용 했다가 최종은 제외함
테스트 데이터에 Augmentation 을 적용해서, 같은 이미지에 대해 증강된 이미지를 추가로 예측하여, 예측된 결과를 앙상블하는 기법이다. 점수가 그렇게 높지 않을때는 TTA 를 적용하니 점수가 확실히 상승하긴 했다. 그런데, 0.92 점과 같이 높은 점수에서는 오히려 TTA 를 적용하니 점수가 떨어지는 현상이 발생하여 최종적으로는 제거 했다.
학습한 모델을 파일로 저장하여 나중에 이어서 학습 할 수 있도록 함
학습에는 시간이 오래 걸릴 수 있다. 그래서 한 에폭이 끝날때마다 학습된 모델을 파일로 저장하고, 이 파일로 나중에 다시 모델 상태를 불러와서 학습을 이어서 하거나, 예측을 할 수 있다.
def save_model_checkpoint(seed, tst_img_size, batch_size, epoch, augment_ratio, model, model_name, optimizer, postfix, fold = 0, folds = 0):
cp_filename = f"cp-{model_name}_sd_{seed}_epc_{epoch}_aug_{augment_ratio}"
if len(postfix) > 0:
cp_filename += f"_{postfix}"
if folds > 0:
cp_filename += f"_fold_{fold}_folds_{folds}"
cp_filename += ".pt"
torch.save(
{
"model": model_name,
"seed": seed,
"tst_img_size": tst_img_size,
"batch_size": batch_size,
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"description": f"{model_name} 모델 epoch {epoch} 까지 학습한 모델, fold: {fold}/{folds}",
},
cp_filename
)
print(f"Model checkpoint saved. filename: {cp_filename}")
def load_model_checkpoint(cp_filename, model, optimizer, device):
checkpoint = torch.load(cp_filename, map_location = device)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
return checkpoint모델의 상태 뿐만 아니라, 모델 학습시 사용했던 파라미터도 함께 딕셔너리에 저장할 수 있다.
다양한 모델 학습
timm 라이브러리에는 많은 미리 학습된 모델들을 제공한다. 허깅페이스에서 해당 모델을 검색하면, 추가로 학습할 때 사용해야하는 이미지 사이즈등의 정보를 확인 할 수 있다.

모델 별로 성능이 다르기 때문에, 최대한 다양한 모델들을 학습해보고 실험을 해봐야 했다. 모델만 잘 골라도 높은 점수를 얻을 수 있었다. 팀원들과 중복 없이 나만 학습해 봤던 모델들은 다음과 같다.
- swinv2_base_window12to24_192to384.ms_in22k_ft_in1k
- densenet121.ra_in1k
- densenet161.tv_in1k
- densenet169.tv_in1k
- densenet201.tv_in1k
- tf_efficientnet_b7.ns_jft_in1k
- tf_efficientnetv2_m.in21k_ft_in1k
자체 평가 의견
잘했던 점
- 수업시간에 알려줬던 기법들을 최대한 적용해 볼 수 있었다. 역시나 성능 향상에 큰 도움이 되었다.
- 다양한 실험을 시도해 보았다. 우리 팀의 서브미션 횟수는 138회로 제일 많다.
아쉬웠던 점
- 팀원 분중에서 OCR 을 사용하신 분이 계셨는데, 나는 이 부분이 대회 규정에 저촉될까 싶어서 시도하지 않았다. 그러나 안해보던 시도를 해보는것은 중요한 것이니, 나중에 제거 하더라도 배우는 자세로 시도해 봤다면 좋지 않았을까 싶다.
인사이트
- 학습 데이터에 에러가 있을 수 있다.
- 배운 내용이 역시나 중요하다.
- 학습시 해상도가 높을수록 성능이 좋다.
소감
이미지 분류 모델의 성능이 예상했던 것 보다 너무 좋았다. 이 정도 수준이면 완벽하진 않지만, 일상의 업무에 적용하면 단순 노동 시간을 획기적으로 줄일 수 있을 것 같다. AI 는 뜬구름 잡는 소리가 확실히 아닌 것 같다. 앞으로 배우게 될 내용 또한 매우 기대된다.
'Upstage AI Lab 3기' 카테고리의 다른 글
| Computer Vision Advanced (0) | 2024.08.20 |
|---|---|
| Computer Vision Basic (0) | 2024.08.20 |
| [2024-07-09~2024-07-22] 아파트 실거래가 예측 대회 (0) | 2024.07.21 |
| 중간 회고 (5) | 2024.07.14 |
| [2024-06-25~07-01] PyTorch (0) | 2024.07.02 |


